Case-insensitive Search Term Highlighting With JavaScript
My partner and I track our shared expenses using a tiny little web-based tool I wrote back around the time we started dating – so now, nine-ish years later, it was about time to add search functionality.
Not wanting to dive too deeply1 into the terrible mess of long-untouched and possibly-gone-feral PHP code that makes up the tool’s2 backend, I decided to do this purely client-side: shipping a list of our roughly 2500 shared purchases to the browser (with the assumption that the development of compute and networking speeds will outpace our accumulation of restaurant visits and things), then hiding those not matching the search term as it’s typed.
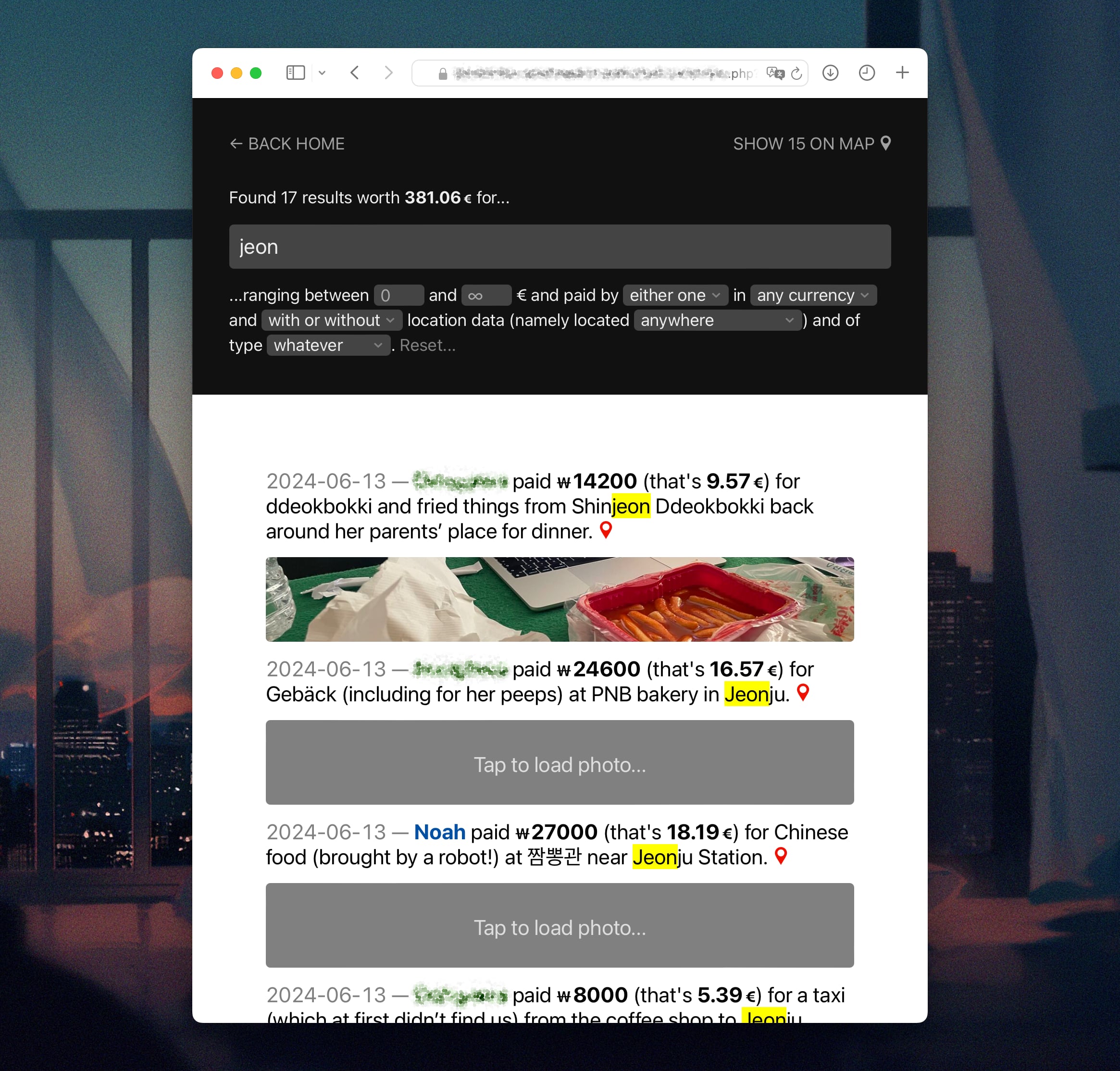
A screenshot of a search that just happens to show off case-insensitive search term highlighting. (Also, some semi-subliminal vacation humblebragging.)
(I’ve since published another blog post about that mysterious “namely located anywhere” dropdown menu – it enables filtering by country and is powered by MariaDB’s geospatial functions.)
Anyway, one small challenge that’s “encapsulate-able” enough to write a blog post about was highlighting occurrences of the search term in a case-insensitive manner – so that searching for “jeon” would highlight both “Shinjeon” and “Jeonju”.
Markup
To set the scene, here’s some HTML closely matching how purchases are marked up (markupped?) in my tool.
<input id="searchbar" value="">
<ol id="purchases">
<li id="p1337">
<span class="date">2024-06-13 -</span>
<span class="who">Noah</span> paid ⋯ for
<span class="description">things and stuff</span>.
</li>
<li>
⋮
</li>
⋮
</ol>
So there’s an input for the search term, then a list3 of purchases, each with an id like p1337 and a span.description that’ll be the only thing considered for search matches. (In my case, the description won’t ever contain any HTML. Keep that in mind if your use case comes without this handy dandy simplifying precondition.)
Highlighting can be accomplished by wrapping the matching parts of a purchase’s description in <mark> tags.
Searching
Given the markup above, we can implement a basic4 search function as follows:
document.querySelector('#searchbar').addEventListener('input', event => {
const searchTerm = event.target.value;
document.querySelectorAll('#purchases li').forEach(purchaseLi => {
const descriptionSpan = purchaseLi.querySelector('span.description');
clearHighlight(descriptionSpan); // remove highlights from previous searches
const match = descriptionSpan.textContent.toLowerCase().includes(searchTerm.toLowerCase());
if (match) {
purchaseLi.style.display = ''; // if previously hidden, show
highlight(searchTerm, descriptionSpan);
} else {
purchaseLi.style.display = 'none';
}
});
});
There’s nothing too fancy going on yet: On each keystroke (or other manner of input) in the #searchbar, the code runs through the list of purchases, checking if each one’s description contains the search term (case-insensitively by means of converting both to lowercase first). If so, a yet-unimplemented highlight(searchTerm, descriptionSpan) function is called. Non-matching purchases are hidden and highlights from previous5 searches cleared.
Highlighting
Without even considering case (in)sensitivity, my first shot at the highlight function was a two-liner:
function highlight(searchTerm, descriptionSpan) {
const nonHighlightedBits = descriptionSpan.textContent.split(searchTerm);
descriptionSpan.innerHTML = nonHighlightedBits.join(`<mark>${searchTerm}</mark>`);
}
Two lines, three issues. (And I’ve written worse code than this.)
- Of course this implementation won’t highlight matches that differ from the search term casing-wise –
String.splitis case-sensitive; there’s no case-insensitive equivalent available in any browsers today. - Even if there was, filling in the correctly-cased variant in each
<mark>tag in line 2 would require somehow capturing them in line 1. Imagine searching for “a” in “Aardvark” – the first match needs to remain a capital A and the two other ones need to remain lowercase. Can’t just use the search term. - Unrelated to functionally-correct highlighting but important nonetheless, adding content to a page by setting an element’s
.innerHTMLproperty to a value containing bits of straight user input opens the door to code injection. Despite this not6 being exploitable here, I’ll get back to it after addressing 1 & 2.
Case-insensitive highlighting
JavaScript’s String.split() function can – instead of a string to split on – also accept a regular expression where each match then yields a split. And, conveniently, JavaScript’s regular expression objects can be created with a case insensitivity flag. So instead of ⋯.split(searchTerm), we can write ⋯.split(new RegExp(searchTerm, 'ig')), quickly and easily resolving issue 1.
…but with a bit of an asterisk – literally: Imagine searching for “A*” in the string “A* Algorithm” both with and without regular expression support. A basic search would of course only match “A*”, but a regex search7 would instead match the two capital “A”s (plus a whole bunch of empty strings).
Considering this accidental regular expression support a bug rather than a feature (your opinion may well differ), I figured out that backslash-escaping all characters carrying a special meaning in regular expressions will again make the highlighter as dumb as it ought to be:
const regEscape = v => v.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
const nonHighlightedBits = descriptionSpan.textContent.split(new RegExp(regEscape(searchTerm), 'ig'));
Correctly-cased highlighting
Now onto issue 2 (i.e., filling in the correctly-cased variant of the match in each <mark> tag). Having switched to splitting by a regular expression instead of a plain string just so happens to help resolve this one, too, since String.split(RegExp) will include any capturing groups at odd indices of the resulting array. So all that’s needed is wrapping the regEscape(searchTerm) bit in a capturing group…
const bits = descriptionSpan.textContent.split(new RegExp('(' + regEscape(searchTerm) + ')', 'ig'));
…and then, when putting things back together, placing a <mark> tag around each odd-indexed element of that array. With all that, the highlight function gains a line, but loses two issues (the code injection one remains – read on):
function highlight(searchTerm, descriptionSpan) {
const regEscape = v => v.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
const bits = descriptionSpan.textContent.split(new RegExp('(' + regEscape(searchTerm) + ')', 'ig'));
descriptionSpan.innerHTML = bits.map((s, i) => i & 1 ? `<mark>s</mark>` : s).join('');
}
Code injection prevention
To guard against code injection, we need to construct a collection of DOM nodes ourselves instead of, as above, letting the browser do that by assigning HTML code to the .innerHTML property of the descriptionSpan element. “Packaging” anything depending on user input (i.e., the matches) within text nodes will prevent parsing and execution of <script> tags someone might’ve sneaked in there.
const highlighted = bits.map((s, i) => {
if (i & 1) {
const e = document.createElement('mark');
e.appendChild(document.createTextNode(s));
return e;
}
return document.createTextNode(s);
});
descriptionSpan.replaceChildren(...highlighted);
This code “manually” assembles a subtree of text and <mark> nodes and hooks it in below the description element, replacing8 its previous contents.
Putting it all together
Here’s the full highlight function for your copy-pasting pleasure. There’s also a little demo if you’d like to try it out first!
function highlight(searchTerm, descriptionSpan) {
// nothing to do if the search field was empty
if (searchTerm.length == 0) {
return;
}
// case-insensitive split while capturing split string
const regEscape = v => v.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&');
const bits = descriptionSpan.textContent.split(new RegExp('(' + regEscape(searchTerm) + ')', 'ig'));
// put back together while surrounding split strings (always at odd indices) with <mark>
const highlighted = bits.map((s, i) => {
if (i & 1) {
const e = document.createElement('mark');
e.appendChild(document.createTextNode(s));
return e;
}
return document.createTextNode(s);
});
// finally, write back onto page
descriptionSpan.replaceChildren(...highlighted);
}
-
Which I did anyway once I got a bit of a flow going, adding a map view and – also overdue – the ability to edit purchases. ↩
-
Which is also why I haven’t open-sourced it. ↩
-
<ol>instead of<ul>(despite, in the screenshot,list-style-type: none) because the list’s ordered by date. Semantic markup, y’all! ↩ -
Basic as in “I didn’t consider performance for a second”, but anecdotally, it’s quick enough to support thousands of entries without noticeable delay (i.e., faster than a round trip to the backend). ↩
-
The
clearHighlight(descriptionSpan)function is justdescriptionSpan.textContent = descriptionSpan.textContent, which effectively replaces any<mark>tags with the text they contain. ↩ -
For two reasons: 1. The only extant instance of this tool is behind a login that only the two of us have access to, and (more importantly) 2. since purchase descriptions don’t contain HTML, searching with a string containing a
<script>tag wouldn’t match any purchases, so thehighlightfunction wouldn’t insert it into the page (nor run at all). ↩ -
Where “A*” means “any number (including zero) of successive ‘A’s”. ↩